算法原理
Logistic回归与多元线性回归实际上有很多相同之处,最大的区别就在于它们的因变量不同,其他的基本都差不多。正是因为如此,这两种回归可以归于同一个家族,即广义线性模型(generalized linear model)。
这一家族中的模型形式基本上都差不多,不同的就是因变量不同。
- 如果因变量是连续的,就是多元线性回归;
- 如果是二项分布,就是Logistic回归;
- 如果是Poisson分布($P(X=x)=\frac{m^x}{x!}e^{-m}$,平均为m时取值为x的概率),就是Poisson回归;
- 如果是负二项分布,就是负二项回归。
Logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释。所以实际中最常用的就是二分类的Logistic回归。
逻辑回归其实是在线性回归的基础上,加上一层逻辑函数 Sigmoid 映射,将预测值限定为(0,1)间。
Sigmoid 函数连续可微分。在z=0时,十分敏感,在z>>0或z<<0处,都不敏感。
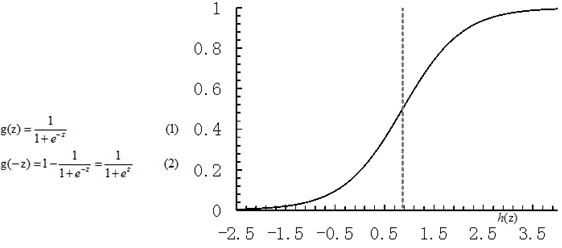
公式推导
逻辑回归定义
假设样本数目为m,样本特征维度为n,$x$的形状为(m, n),$y$的形状为(m,),$y$的取值为0或者1。
对应的,$w$的形状为(n, 1),$b$形状为(1,1)。
逻辑回归的初始抽象为下式,对于$x^{(i)}$的每个特征$x_j^{(i)}$,求解一个权重$w_j$,以及一个常数项(截距)$b$,使得经过Sigmoid变换得到的加权预测值与真实值尽可能相等。
通过将$w$和$b$合并为$\theta$,再将以上两个式子代入,有:
该预测函数表示分类结果为1时的概率。因此对于输入点x,分类结果为类别1和类别0的概率分别为如下公式:
损失函数
对于一组数据集,样本数据x={x1, x2, … , xm}对应的观测值为y={y1, y2, … , ym}。那么可以知道样本{x1, x2, … , xm}取到观测值{y1,y2,...,ym}的概率为:
这一概率随 $\theta$的取值而变化,它是 $\theta$的函数,称 为样本的似然函数。
而某个样本 $x_i$取值为 $y_i$的后验概率如下形式:
假设分类器分类足够准确,此时对于一个样本,如果它是属于1类,分类器求出的属于1类的概率应该尽可能大,即$p(y=1lx)$尽可能接近1;如果它是0类,分类器求出的属于0类的概率应该尽可能大,即$p(y=0lx)$尽可能接近1。通过上述公式对二类分类的情况分析,可知我们的目的是求取参数 $\theta $,使得 $L(\theta) $对观测值的分类结果尽可能取最大值。
对其取对数,可得到以下公式,即我们要求取 $\theta $,使得下式在样本数据上取值最大:
然而实际上我们定义的损失函数是求最小值,于是,很自然的,我们想到对式子加一个负号,再取平均值,就变成了求最小值的问题,这就得到了逻辑回归中的损失函数,优化使其最小:
定义 $y’=h_{\theta}(x)$,那么以上式子简化为
梯度下降
对应参数$\theta_j$的求导为:
第三步用到了Sigmoid函数的求导:
第五步是通分再化简。
最后通过梯度下降,更新参数 $\theta $:
拓展
场景回归具有计算代价低、速度快、容易理解和实现的优点,但同时容易欠拟合、分类和回归的精度不高;其常采用AUC来评估。
多元逻辑回归
二元逻辑回归可以一般化为多元逻辑回归用来训练和预测多分类问题。对于多分类问题,算法将会训练出一个多元逻辑回归模型, 它包含K-1个二元回归模型。给定一个数据点,K-1个模型都会运行,概率最大的类别将会被选为预测类别。具体可以参考逻辑回归基础

逻辑回归和SVM
SVM的损失函数为: $ J=\frac{1}{m}\sum_{i=1}^{m}(1-y_i[w_0+x_i^Tw_1])^++\lambda||w_1||/2 $
LR的损失函数为: $J=\frac{1}{m}\sum_{i=1}^{m}-log(g(y_i[w_0+x_i^Tw_1])+\lambda||w_1||/2) $
其中 $g(z) $为 $sigmoid $函数。
将两者统一起来,即 $J=\frac{1}{m}\sum_{i=1}^{m}Loss(y_i[w_0+x_i^Tw1]) + \lambda||w_1||/2 $
也就是说,他们得主要区别是逻辑回归采用得是log loss,而svm采用得是hinge loss即 $E(z) = max(0, 1-z) $
SVM损失函数为 $Loss(z)=(1-z)^+ $
LR损失函数为 $Loss(z)=log(1+e^{-z}) $
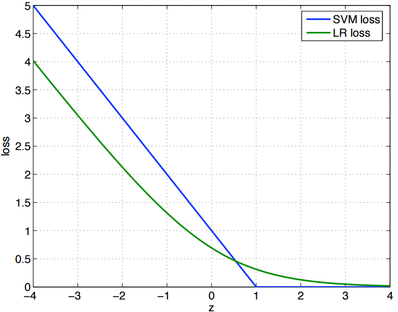
其实,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
SVM的处理方法是只考虑 support vectors,也就是和分类最相关的少数点,去学习分类器。
而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重,两者的根本目的都是一样的。
Python 实现
1 | # -*- utf-8 -*- |
1 | {'neg_log': 0.08890522978727333, 'accuracy': 0.9649122807017544} |
Scikit-learn API
1 | from sklearn.linear_model import LogisticRegression |
1 | {'neg_log': 0.09145479629044562, 'accuracy': 0.9649122807017544} |